(This one is really long and I haven't proof-read it in the slightest)
I haven't written anything for a while. I spent part of the time resting on the laurels of having more than 3 people read a tweet that I wrote. But mostly I was just taking the deep plunge back into good, old, despairing research.
Also, I got _engaged_ to another human; thus expenditure of more time, more planning etc. Fortunately, in this line of work, there is only a negligible chance of being scooped by the latest papers on eprint.
I could probably talk for a while on something interesting to most people. However, I've started noticing that the realms of conversation and thought-spaces that I inhabit are slowly converging into a state of cryptotopia. This is bad, and maybe one day I could write something not about research. BUT, for now I'm just gonna reinforce the point by talking about some shit that no-one will understand. Enjoy (or leave, do whatever is good for you -- you have time on your hands. There is probably a new article on millennial anxiety to be read, somewhere).I've done some drawings in this post. They're done on Google Keep and thus they are the output of a perfect storm of bad drawing and limited functionality. Sorry.
multilinear maps
Part of my research is spending time thinking about these things called multilinear maps (MMAPs). A theoretical primitive in cryptography that could lead to some powerful applications (e.g. attribute-based encryption, indistinguishability obfuscation). Multilinear maps currently manifest themselves as graded encodings schemes, the known candidates being GGH13, CLT13, GGH15. However, most applications using these candidates are broken; in cryptographic terms this means that an adversary can reveal the secret parameters of the design in efficient time. If you want a quick summary then I contribute to a website that summarises recent constructions and attacks.
There are some exceptions to this rule (certain cases of IO etc.) but relying on MMAPs for constructing something is tantamount to proving it impossible to instantiate. This is not a strict impossibility result, but it's a good idea to avoid them when possible.
what are they?
The name multilinear maps implies a strong link to some established mathematical concept. Traditionally we would think of a group structure with gi ∈ Gi, and a target group Gt. A multilinear mapeover Gi,Gt would act in the following way:
kThis,
kis usually a sequence of bits of a certain length. Usually a longer key is better in terms of security. A (symmetric) encryption algorithm
Etakes a message
mand computes E(k,m) -> c. Here,
cis an encryption of your message -- it is known as a ciphertext. For
Ethere is usually an algorithm
Dthat satisfies D(k,c) -> m, i.e. it reverses the encryption and reveals the message. There is also a notion of
asymmetricencryption but that's not really important now.
c2 is equivalent to directly computing E(k,m1+m2) -> c+. Moreover, we have the same for multiplication i.e. cx = c1 xc2 is equivalent to computing E(k,c1c2) (we write
,xbecause we cannot always perform additions and multiplications directly). Homomorphic encryption is widely used in solving problems regarding cloud-computing scenarios. Computing over the ciphertexts requires no access to the original key so operations can be outsourced without revealing secret data.
levelabove in the computation. For additions the level does not change, although computation is only defined for encryption inhabiting the same level. Multiplications can also obey this demand; though we can also define multiplications for ciphertexts on different levels where the resulting level is usually determined by adding together the corresponding levels. I've drawn a terrible picture to illustrate this below (hopefully it's clear that the highlighting denotes the level occupied after the given operation).
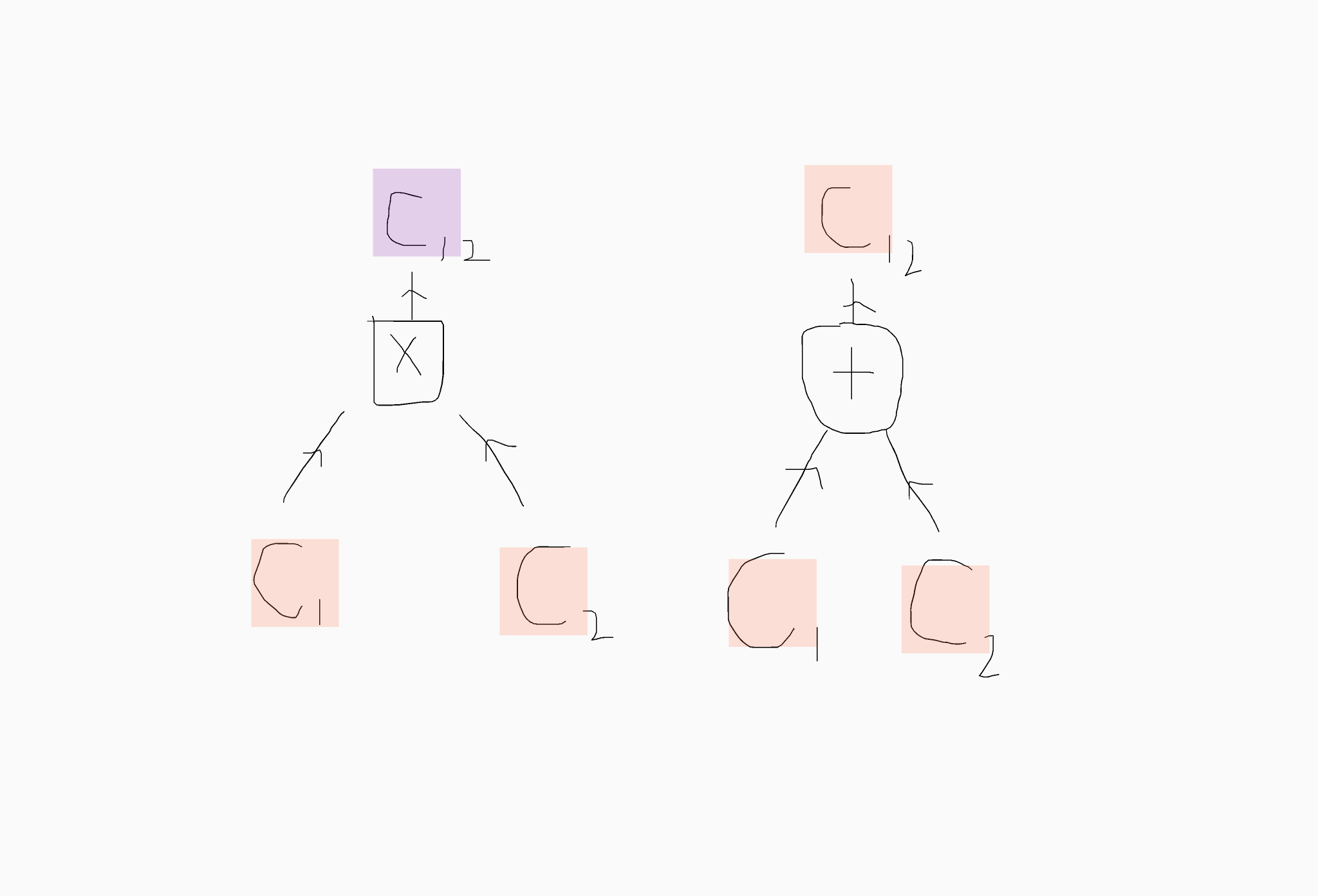
Understanding this property is not terribly important so don't worry if the explanation is not good enough.
homomorphic encryption schemeThe difference between an MMAP and homomorphic encryption is that we allow a zero-test at the top-level of computation. Imagine that our messages m1,m2 from the original encryptions are integers (perhaps modulo q). Let c∂ be the ciphertext at the top-level. Then a zero-test algorithm
ZTallows someone to publicly evaluate whether c∂ is an encryption of
0or not. It may not be apparent why this is useful but notice that in a homomorphic encryption scheme, learning the value encrypted in c∂ requires access to the secret key k used in encryption.
Here is a quick diagram to describe how the computation works. The different colours indicate additive and multiplicative operations on the different levels of the graded encoding scheme.
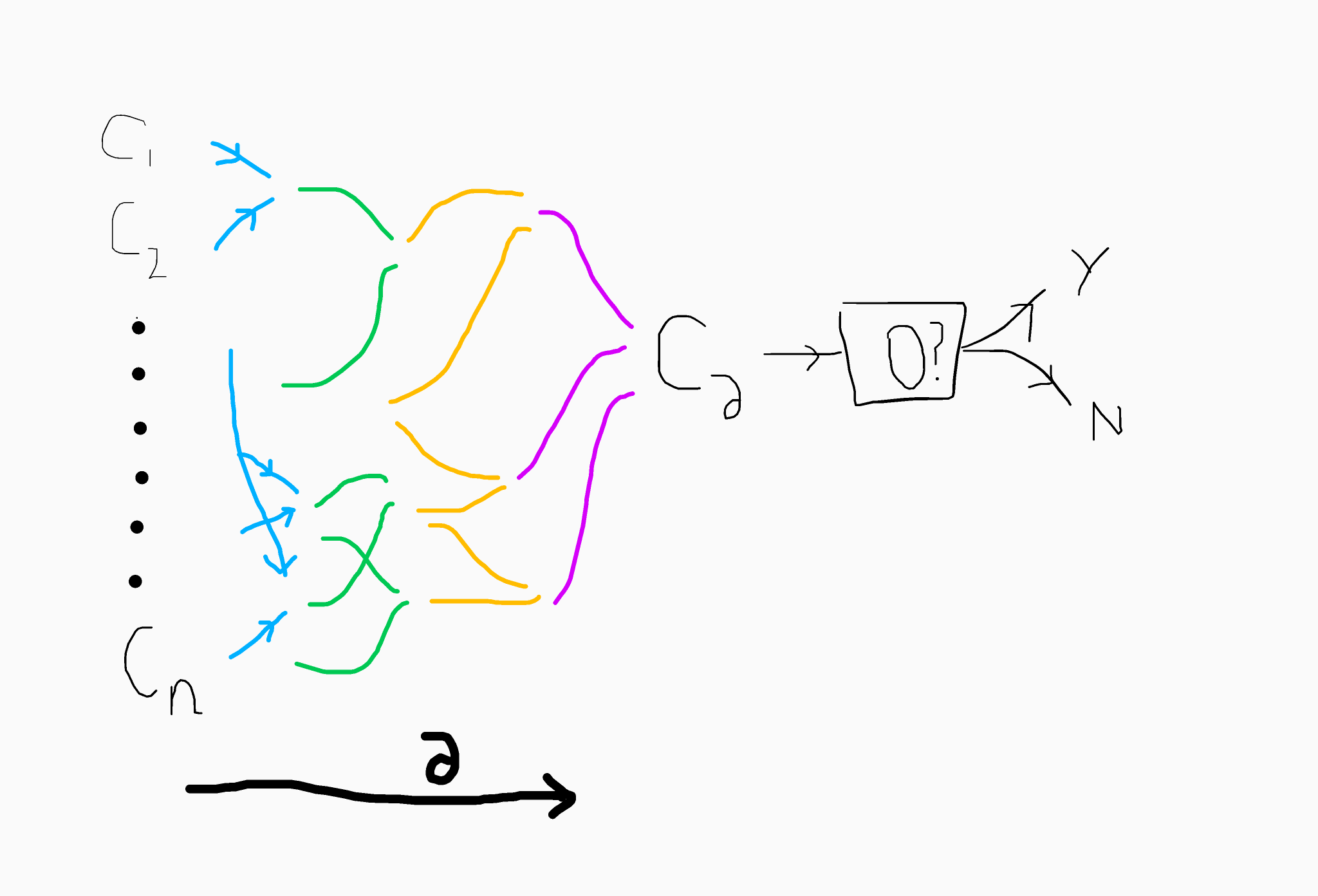
The zero-test algorithm is a powerful piece of kit. It essentially allows public evaluation of functions on encrypted data (where there is no distinction between non-zero final values). As an example, this paradigm is central behind the idea of evaluating obfuscated functions on public inputs. Theoretically the zero-test should only be applicable after honest and well-formed functions have been evaluated. Furthermore, a functioning MMAP in this regard would allow multiparty non-interactive key exchange (currently two-party key exchange is central to providing encryption between clients and servers in internet transactions).
The problem with MMAPs is that the zero-test procedure leads to all kinds of problems. Essentially, current constructions of MMAPs are unable to provide the functionality without surrendering security for their main applications. I'm not going to go into the details of all the constructions but we can safely say that it becomes fairly trivial in most situations to learn secret parameters of the schemes. As such, what we currently have is useless in a cryptographic sense. Or so we thought(/think?)...
GGH15
We've come to the part where I'm going to start describing an actual MMAP construction. I'm assuming if you made it here that you're at least interested in the topic. So I'm gonna make the additional assumption that you understand maths and/or crypto, apologies if I lose you along the way.
GGH15 is the third and most recent construction of a multilinear map-like scheme -- developed by Gentry, Gorbunov and Halevi.
Quick example: Let X,Y be uniform matrices of dimension m x n (entries sampled from ZZq). We sample X using the trapdoor procedure given by Micciancio and Peikert '12. We refer to Dy as the encoding of S on the path X -> Y. For correctness we require that S is a small matrix.
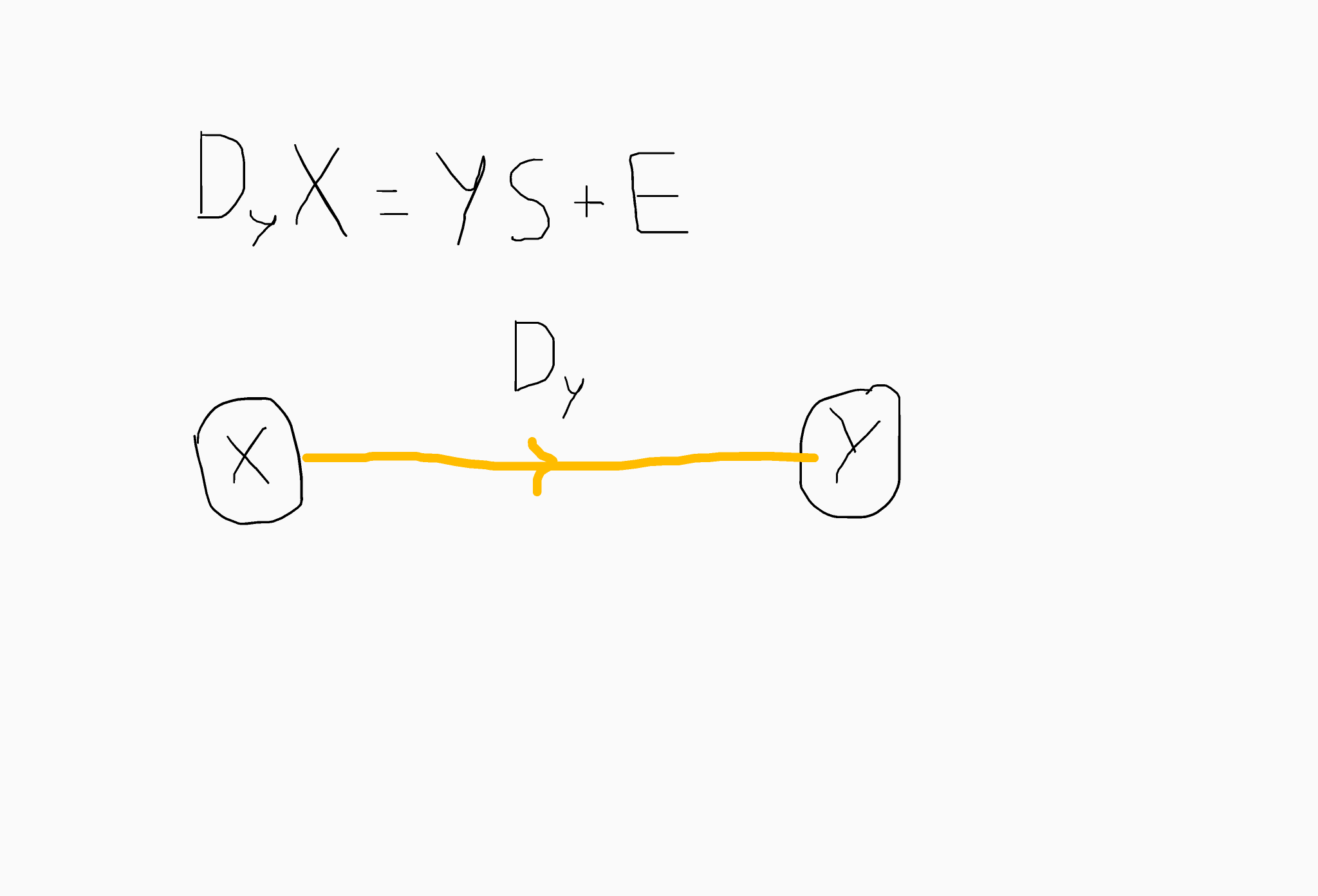
In essence, we can construct a graph-based topology if we know trapdoors for multiple matrices. We can then define multiplications for encodings on disjoint but connected paths. That is, if Dy, Dz are encodings for paths X->Y, Y->Z respectively. Then DyDz is an encoding for the path X->Z. We can add together matrices that are on the same path segment. Verifying the correctness of these computations is simple given the structure of the LWE samples above. Finally, we can check whether two matrices D1 and D2 encode the same value if they represent paths with the same sink node.
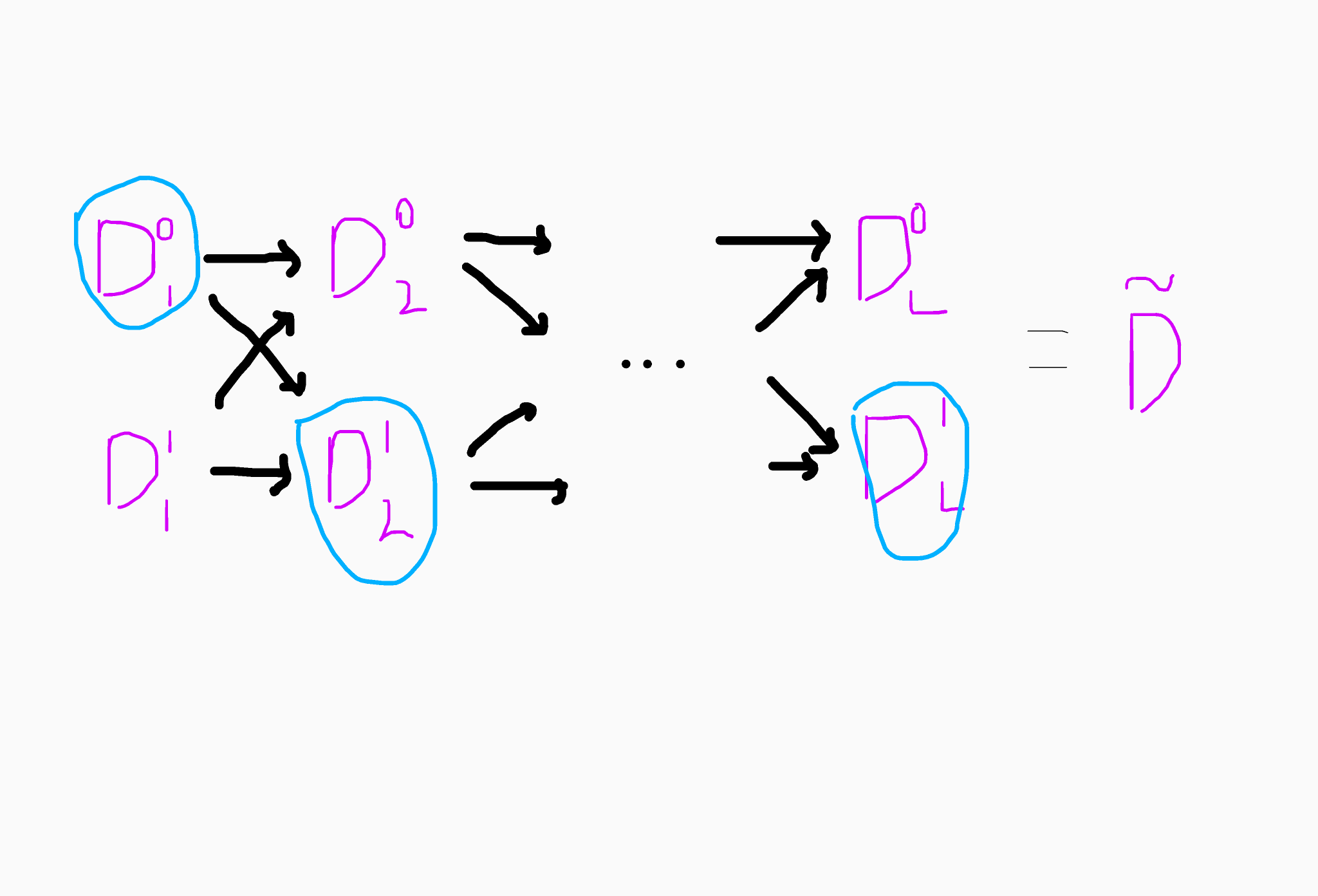
The diagram below gives a more interesting topology.
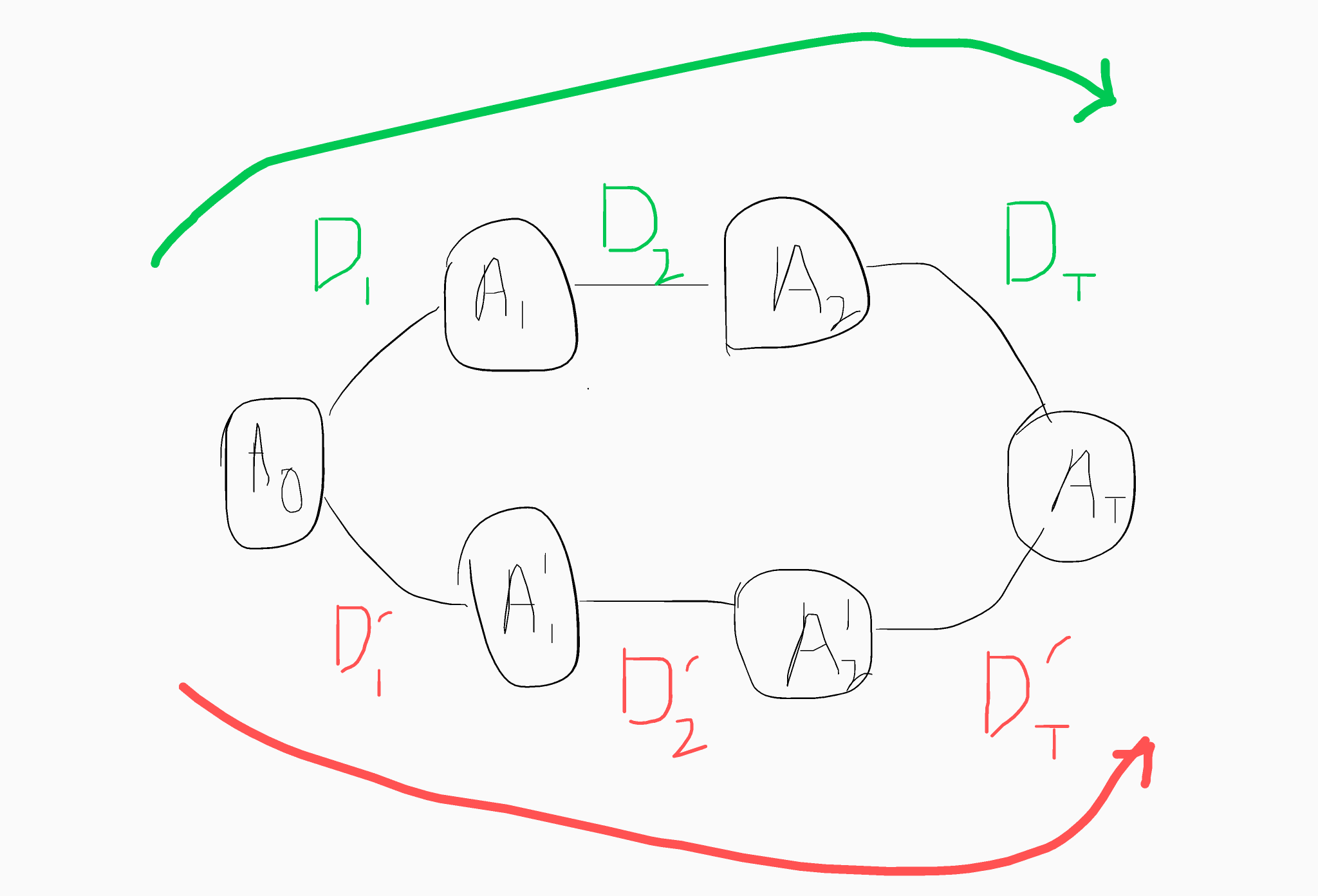
We can multiply D1, D2 and DT to get an encoding D for the path 0 -> T. Likewise we can do the same for D1', D2', DT' to get an encoding D'. We can check if D and D' encode the same value by computing p = (D-D')A0. If p is sufficiently small then this implies that (D-D') is equal to zero and hence the result.
We can define a commutative variant of this scheme where A,S and E follow a ring-based approach.
weaknesses
This graph-based topology is slightly more expressive than the previous level-based design. Zero-testing can now be performed for any encodings with the same sink node. This includes encodings that do not represent the entire, defined path. This contrasts with previous MMAP attempts where zero-testing can only be performed after the top-level is reached.
Also, encodings of zero are catastrophic for security. An encoding of zero on a path X->Y takes the form:
DyX = E
and thus we can say that Dy is aweak trapdoormatrix for X. This can be leveraged by evaluators for computing their own encodings in the constructed system (which should not be possible). For typical applications, encodings of zero are required as part of functionality (this includes for proving the hardness of a multipartite key exchange, for example). In other applications such as IO, there have already been breaks on candidate obfuscators that use the GGH15 MMAP.
strengths?
So; why am I sitting here, racking up >1700 words (so far), telling you about GGH15? More importantly, if you got this far, why in god's name are you still reading? Well, this may sound crazy, but you can actually build some stuff with these things; WITH HARDNESS GUARANTEES dun, dun, duuuuuuuun. In short, if we onl deal with encodings that are sampled in the correct way for LWE distributions (e.g. Gaussian sampled) then we have that DyX = YS+E is a valid LWE sample. If we can build path-based computations using encodings representing secrets of this form then we can prove the construction secure using standard hybrid arguments for replacing LWE samples with uniform elements. As a result, an adversary who is handed elements that are uniformly sampled from Zq or whatever, has no chance of learning secret parameters of the scheme and we're done, qed.The exposition above is drastically simplified, but this is a model that has become a focal point for developing new theoretical constructions based on standard assumptions. Notice that anything we build from GGH15 relying only on LWE-hard secret distributions is built using only the hardness of LWE (which is a standard assumption -- if you hadn't heard). In particular, we have seen new constructions of obfuscators and specific PRF functionalities that were previously impossible to derive from standard assumptions (e.g. they used IO or straight multilinear maps previously). In the final pieces of this post I will go over two of these constructions and hopefully show differing ways of using GGH15 as a sound, constructive primitive.
a secure obfuscator for wildcard-string comparison mechanism from GGH15
Brakerski, Vaikuntanathan, Wee and Wichs that isn't necessarily implied by standard RLWE.
Their obfuscator takes a string containing wildcards and obfuscates it, such that an evaluator can check that their own strings are equal (save wildcard locations) to the obfuscated string. The motivation behind such a construction is situations such as password/credential checking, where it may be necessary to limit access to certain privileged users of a system.
Ignoring wildcards for now and simplifying the design massively, imagine we have a string of L bits b1,...,bL. We can sample Gaussian distributed values s1,...,sL and r1,...,rL. We will encode the values si with the matrix Di^bi and the values ri with Di^(1-bi).
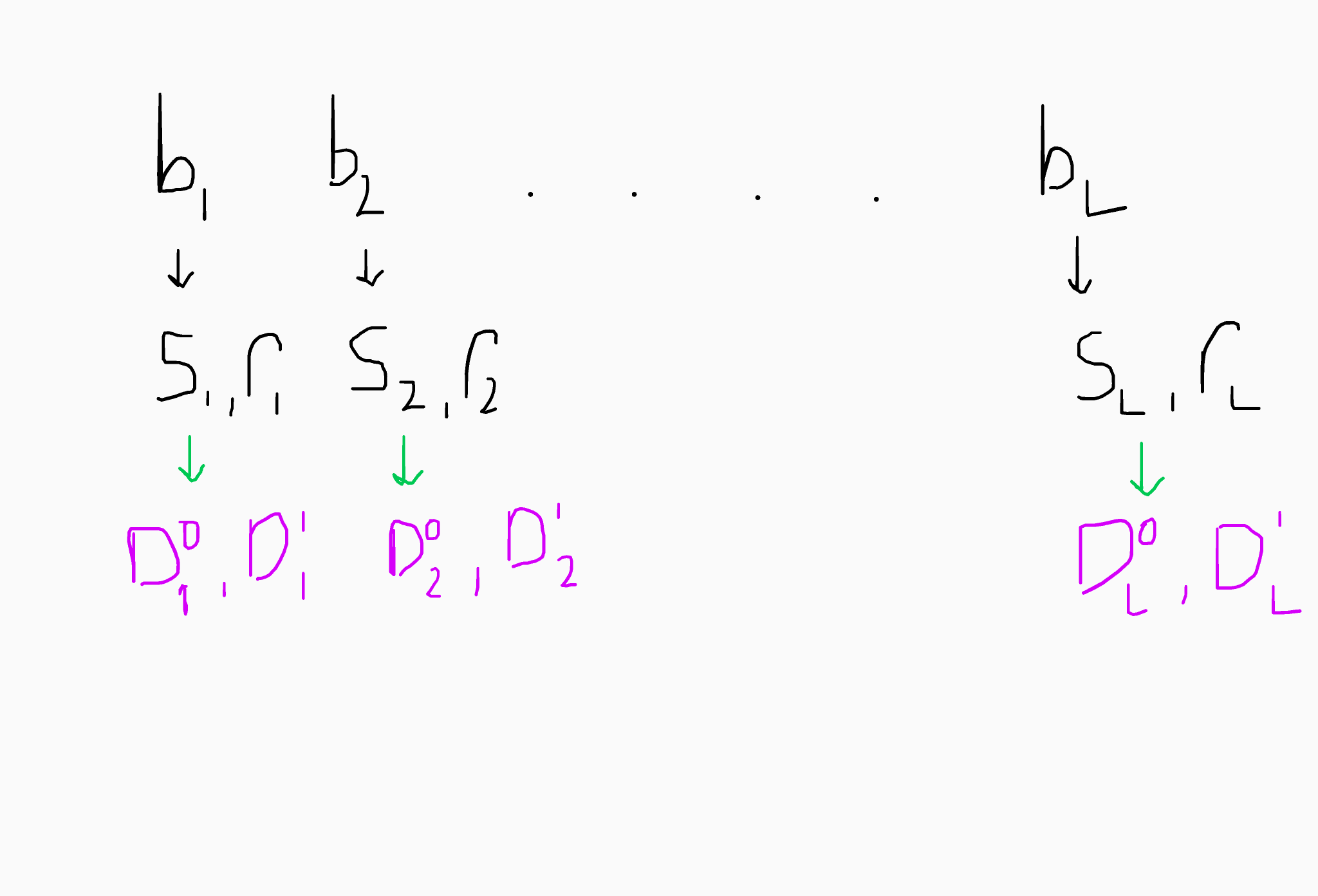
In essence, we will construct oblivious branches in the program of the form below. The encodings are defined along a path of disjoint segments from 1->L+1, where there is a pair of matrices for each edge.
Let's talk about security. We'll ignore the entropic RLWE assumption for now and focus on how RLWE is used for proving security. The authors actually derive a hardness property known as GXDH. This property is interesting to check out, but I will only give a simple rundown of how security works. Notice that each pair of matrices Di0,Di1 represent distributions of the form DibAi = A(i+1)wi + e, where wi is some Gaussian sampled element. We can therefore conduct a hybrid proof by switching out each of these encoding matrices for a random small matrix. This holds by the hardness of LWE, and assuming that the function that we compute contains a string of high-enough entropy from a large distribution.
Notice, that the obfuscator now protects a somewhat evasive/font> function, as the string-equality test effectively represents a point function. This is important for security, and it is currently not known how to extend the GGH15 functionality to cases where the function that is obfuscated is not evasive. In these cases it would be easy to create encodings of zero and further it would not be possible to replace the encoded matrices with random encodings since the adversary would be able to test whether it was in the real-world or simulated world.In any case, providing that the function is sufficiently evasive we can replace the program with random small matrices. In this simulation the adversary cannot learn anything about the underlying string and thus security holds (assuming RLWE). woop.
a constraint-hiding PRF for NC1 circuits
The second (and last you'll be pleased to hear) that I'm gonna talk about is a constrained PRF for NC1 circuits from straight LWE by [Canetti and Chen]. It uses GGH15 if you hadn't got the theme yet.
The work that creates this primitive allows constraints to be submitted as NC1 circuits. For the purposes of saving the bored reader I will talk about a simplified case where the constraint is a bit string. The NC1 circuit version can be bootstrapped on by using Barrington's theorem (who would have guessed). In the bit-string variant, the constraint is a string (with possible wildcards) where the correct PRF output is given if the string equality check succeeds (or vice-versa). The actual construction of the PRF is very similar to the conjunction obfuscator above, except that DT is no longer provided. Furthermore, for bits that have to be considered in the check, we replace the corresponding unused matrix for the opposing choice of bit with a random small matrix immediately.
The PRF outputs an LWE sample when the equality condition is met, and a uniform element when it is not. The constraint is hidden given the hardness of the LWE problem.
(If this made no sense I'm sorry but I have spent a whole saturday writing this thing and now I'm tired).
other stuff
There is a bunch of new and exciting stuff happening using GGH15 as a starting point. Here is a few examples:
some problems that may be solvable?
One of the interesting things to come out of this is that we can clearly do a lot more with LWE-like assumptions than was previously thought possible. We are limited to the path-based topology enforced by GGH15 but, in particular, this may be enough for some expressive functionalities. These are some of the research areas that I think may be able to benefit from GGH15-style computation:
This is the end I think. Maybe I'll update this with future work as it arrives?